There’s a moment every SOC analyst hits sometime in their first month or two on the job. It usually happens around eleven on a Tuesday morning, when the coffee has worn off and the
queue hasn’t gotten any shorter.
You realize the alert you just closed as a false positive is the same one you closed three hours ago. Same signature, same source, same outcome. The platform produced it again and stuck it back at
the top of the list, because the platform doesn’t know it was already triaged, doesn’t know how it resolved, and doesn’t seem to care.
You close it. You move on. And somewhere around the fortieth time you do this, you start
wondering what exactly the AI in your AI-powered noise reduction platform is doing, because whatever it’s doing, it isn’t this.
The gap between what the marketing says about noise reduction and what the platform actually
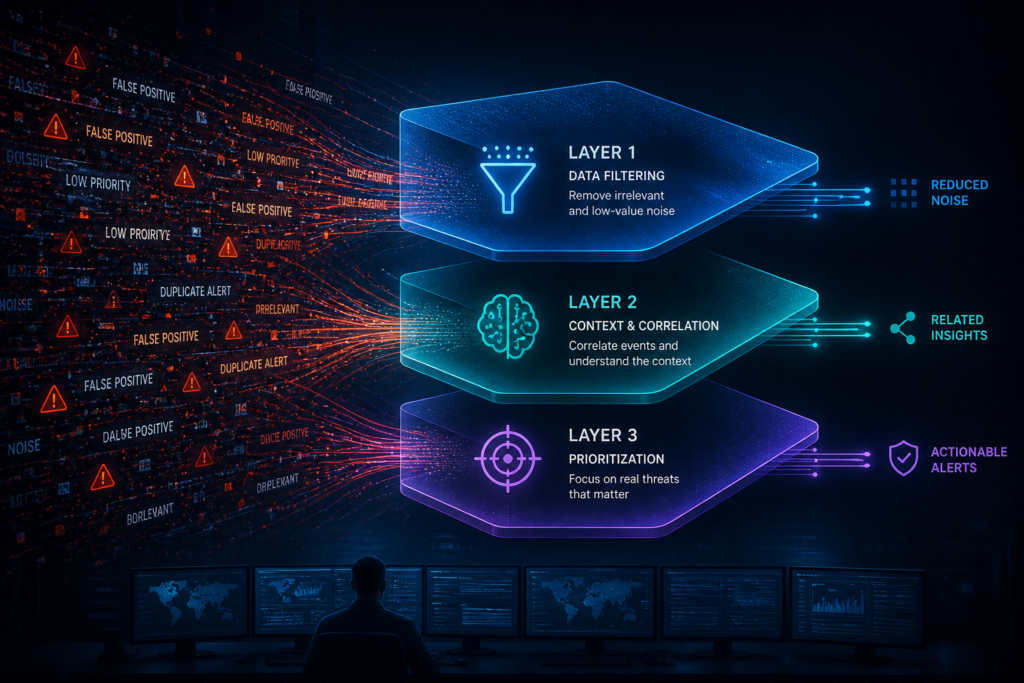
does in a SOC is everywhere in this category. The reason it’s everywhere is that most of these platforms are doing one thing and calling it three.
What they‘re really doing
Severity scoring. That’s it.
Some model, somewhere in the stack, looks at an alert and assigns it a number. The number gets tuned by thresholds, weighted by configurable factors, maybe run through a classifier, and what comes out the other end is a sorted list. High at the top, low at the bottom, your analysts work their way down.
Severity scoring is fine. It’s a real and useful thing. But it isn’t noise reduction, and pretending it is causes every conversation I keep having with SOC leaders about why their queue still feels like
a queue.
An alert can be noise for at least three completely different reasons, and a single score has no way of telling you which one you’re looking at.
It can be noise because the platform has no business context to know the asset doesn’t matter. The system underneath might be a decommissioned test box nobody owns. The alert is real but
the target is irrelevant.
It can be noise because the platform has no memory of having seen this exact pattern fire ninety times in the last three months and resolve harmless every time. The signature is real but the meaning is not.
It can be noise because the platform can’t see that the alert is one piece of something bigger, and looking at it on its own is the wrong move. The alert is real but the unit of analysis is wrong.
These are not the same problem. They need different filters. A platform that throws one number at all three is doing about a third of the job.
When the platform has no business context
You’ve got a vulnerability scanner spitting out CRITICALs at six or eight an hour. You scan the list. Two of them are on systems anyone actually uses. The rest are on test boxes that haven’t been touched in a year, on a printer in the third-floor copy room, on a forgotten dev VM in a subnet nobody owns anymore.
The CVSS score on all of these is the same as the CVSS score on your payment processor. The scanner can’t tell the difference. If you’re filtering by severity alone, you can’t filter these out. The
vulnerability is real. It’s just that nobody should care, and the reason nobody should care has
nothing to do with the alert itself.
What you need is something running alongside the score that understands your business. What
this system does. What data it holds. Who depends on it. What’s load-bearing for the company and what’s a test environment nobody has touched in a year. None of that lives in the alert. All of it lives in your asset model, assuming the platform can read it.
This is probably ninety percent of the noise problem right here. Not because the math is hard but because the platform needs business context that isn’t in the alert. The vulnerability on the test
box and the vulnerability on the production database look identical to anything that’s only
reading alerts. They look completely different to anything that knows what those systems are to
the business.
When the platform has no memory
2:14 AM on a Tuesday. An alert lands. Encoded PowerShell command, executed by a service account, on a backup server. The platform flags it as high severity. Encoded PowerShell is a known indicator of malicious activity, and the platform is technically correct.
The on-call analyst opens the alert. Spends fifteen minutes pulling logs, checking the parent process, looking at the service account’s recent activity, and figures out it’s a scheduled job that runs every Tuesday at 2:14 AM and has been running cleanly for the last seven months. He closes
the alert. Goes back to bed.
Next Tuesday at 2:14 AM, the alert fires again. Different on-call analyst this time. Same fifteen minutes. Same conclusion. Same close.
This is the part I find genuinely frustrating about most platforms. They have no memory. Every alert is the first alert. The pattern that fired ninety-six times last quarter and resolved benign
every single time looks identical on firing number ninety-seven.
A senior analyst catches this in three seconds because she’s seen it before. A junior analyst spends a full investigation cycle on it. The platform, which is supposedly doing the analyst’s job, will produce the same alert tomorrow with the same severity and the same urgency, like nothing
has ever happened.
What’s needed is a filter that remembers. When an alert lands, the system asks: have we seen this pattern before, on this asset, in this environment? How did it resolve? If the answer is “ninety-six times, all benign,” that should change how the alert is treated. Not vanish it, because something
might genuinely have changed, but at the very least not put it at the top of the queue with the same urgency as a brand new alert nobody has ever seen.
Here’s the thing about this filter that the industry doesn’t talk about enough. It doesn’t work right away. Day one it has nothing to compare against. Month one it’s still warming up. Around month three you can really start to feel it. By month six it’s doing more work than the severity score is. This is also why a platform that has historical correlation looks roughly the same as one
that doesn’t in a thirty-day pilot. The pilot is the worst possible test for the filter that matters most over the long run.
And this filter cannot be bought off the shelf. It has to learn from your data. Your incident history, your false positive patterns, the specific way your environment behaves at 2 AM on a Tuesday. A vendor can ship the framework. They cannot ship the memory. The memory belongs to your
SOC, and a platform that doesn’t ingest it is throwing away the most valuable signal in the building.
When the alert isn‘t the unit
This one is the most important and the hardest to demo.
Ten alerts come in over forty-five minutes. A failed login. A successful login from a country the user has never logged in from. A brief privilege escalation that gets reverted. A small data
transfer to a cloud storage bucket. A process spawned from an unusual parent. A few more, all in the same window, all involving the same user and a couple of related systems.
Each individual alert is yellow. Medium severity. None of them, on their own, would clear the
threshold for anyone’s immediate attention. The platform handles them as ten separate events. Ten separate tickets, ten separate close-outs. Possibly ten different analysts if the SOC is busy.
A human looking at all ten together sees something obvious. Same user, same hour, an arc that walks from initial access to lateral movement to staging. Each alert is a piece. The incident is the pattern.
This is the failure mode that gets SOCs breached, and it doesn’t happen in a dramatic way. It’s not the alert that screamed and got ignored. It’s the ten alerts that whispered and got handled separately because the platform didn’t know they belonged together.
The fix is conceptually simple. Cluster related events. Identify the entity they have in common. Elevate the cluster as one case at the appropriate severity, which is almost always higher than any individual alert in it. Ten yellows become one orange. The analyst sees the case, not the alerts.
The reverse case gets less attention but matters too. Ten high-severity alerts all fire in five minutes because one upstream system burped, and the right move is to roll all ten into one
investigation rather than spend an hour treating them as separate incidents. Same mechanism, opposite direction.
What this filter buys you day to day is a conversion of alert volume into case volume. Thirty thousand alerts become three hundred cases. Not because most of them got thrown away.
Because they got resolved into the cases they actually belonged to.
A severity score can’t do this. It scores each alert against a fixed scale and moves on. The pattern across alerts is invisible to it.
What the pitch hides
The standard pitch in this category is that the platform does all of this. AI-powered noise reduction. Machine learning models. A big percentage of alerts suppressed.
What you’re actually getting, in most cases, is severity scoring with tunable thresholds. Maybe an asset enrichment feature that pulls a CMDB tag onto the alert, which is not the same thing as
scoring the alert against an asset risk model. Maybe some deduplication that collapses identical alerts inside a short time window, which is not the same thing as identifying behaviorally related events across different alert types.
Real noise reduction means three mechanisms running in parallel, each looking at a different signal, each catching a different kind of noise. Business context catches the alert on a system that
doesn’t matter. Historical correlation catches the alert you’ve already seen and already triaged. Cross-alert clustering catches the alert that’s actually a fragment of something bigger.
Take any one of them out and a category of noise survives. Take all three out and you don’t have noise reduction. You have a sort order.
What to ask
When you’re evaluating a platform in this category, ask which mechanism catches which kind of noise. Not the percentage they reduce. The mechanism. If the answer is some version of “our model figures it out,” that’s a single score with marketing on top. If you hear business-context filtering, historical pattern matching, and cross-alert clustering described as three separate things doing three separate jobs, you’re probably talking to somebody who’s actually thought about the problem. And if you’re an analyst sitting at your station tomorrow morning, closing the same false positive for the fortieth time, that’s the test. The platform you’re using either knows it’s the fortieth time, or it doesn’t. If it does, the alert won’t be there next Tuesday. If it doesn’t, you already know how this story ends.